ShardingJDBC
一个客户端数据库分片库
原理
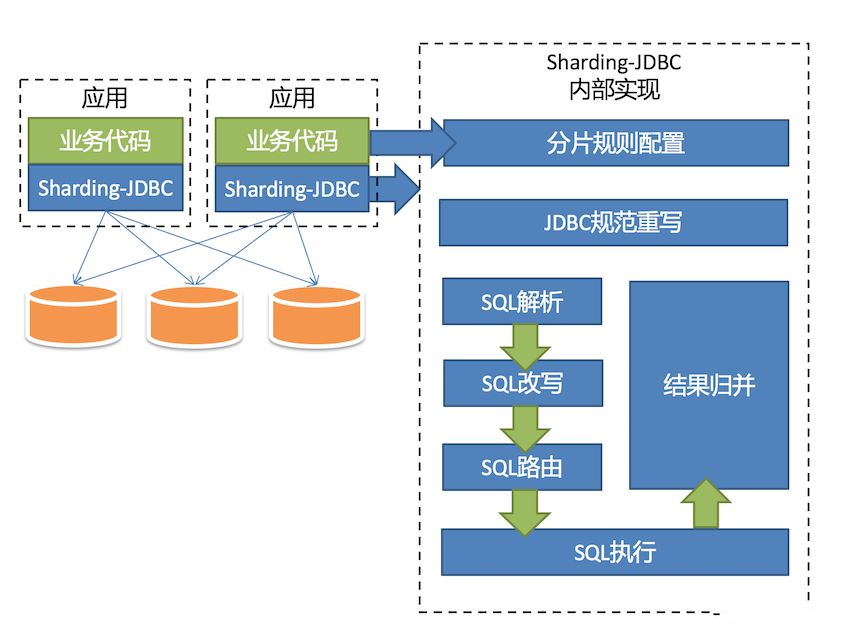
简单使用
<dependency> <groupId>io.shardingjdbc</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>2.0.3</version></dependency>#shardingjdbc配置sharding: jdbc: data-sources: ###配置第一个从数据库 ds_slave_0: password: 123 jdbc-url: jdbc:mysql://192.168.182.132:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true driver-class-name: com.mysql.jdbc.Driver username: root ###主数据库配置 ds_master: password: 123 jdbc-url: jdbc:mysql://192.168.182.131:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true driver-class-name: com.mysql.jdbc.Driver username: root ###配置读写分离 master-slave-rule: ###配置从库选择策略,提供轮询与随机,这里选择用轮询 load-balance-algorithm-type: round_robin ####指定从数据库 slave-data-source-names: ds_slave_0 name: ds_ms ####指定主数据库 master-data-source-name: ds_master@Configuration@EnableConfigurationProperties(ShardingMasterSlaveConfig.class)@Log4j2// 读取ds_master主数据源和读写分离配置@ConditionalOnProperty({ "sharding.jdbc.data-sources.ds_master.jdbc-url", "sharding.jdbc.master-slave-rule.master-data-source-name" })public class ShardingDataSourceConfig { @Autowired private ShardingMasterSlaveConfig shardingMasterSlaveConfig; @Bean public DataSource masterSlaveDataSource() throws SQLException { final Map<String, DataSource> dataSourceMap = Maps.newHashMap(); dataSourceMap.putAll(shardingMasterSlaveConfig.getDataSources()); final Map<String, Object> newHashMap = Maps.newHashMap(); // 创建 MasterSlave数据源 DataSource dataSource = MasterSlaveDataSourceFactory.createDataSource(dataSourceMap, shardingMasterSlaveConfig.getMasterSlaveRule(), newHashMap); log.info("masterSlaveDataSource config complete"); return dataSource; }}@Data@ConfigurationProperties(prefix = "sharding.jdbc")public class ShardingMasterSlaveConfig { // 存放本地多个数据源 private Map<String, HikariDataSource> dataSources = new HashMap<>(); private MasterSlaveRuleConfiguration masterSlaveRule;}分表
private DataSource buildDataSource() { // 1.设置分库映射 Map<String, DataSource> dataSourceMap = new HashMap<>(2); dataSourceMap.put("ds_0", createDataSource("ds_0")); // dataSourceMap.put("ds_1", createDataSource("ds_1")); // 设置默认db为ds_0,也就是为那些没有配置分库分表策略的指定的默认库 // 如果只有一个库,也就是不需要分库的话,map里只放一个映射就行了,只有一个库时不需要指定默认库, // 但2个及以上时必须指定默认库,否则那些没有配置策略的表将无法操作数据 DataSourceRule rule = new DataSourceRule(dataSourceMap, "ds_0"); // 2.设置分表映射,将t_order_0和t_order_1两个实际的表映射到t_order逻辑表 TableRule orderTableRule = TableRule.builder("t_order").actualTables(Arrays.asList("t_order_0", "t_order_1")) .dataSourceRule(rule).build(); // 3.具体的分库分表策略 ShardingRule shardingRule = ShardingRule.builder().dataSourceRule(rule) .tableRules(Arrays.asList(orderTableRule)) // 根据userid分片字段 .tableShardingStrategy(new TableShardingStrategy("user_id", new TableShardingAlgorithm())).build(); // 创建数据源 DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule); return dataSource; } private DataSource createDataSource(String dataSourceName) { // 使用druid连接数据库 DruidDataSource druidDataSource = new DruidDataSource(); druidDataSource.setDriverClassName(className); druidDataSource.setUrl(String.format(url, dataSourceName)); druidDataSource.setUsername(username); druidDataSource.setPassword(password); return druidDataSource; }public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> { // sql 中关键字 匹配符为 =的时候,表的路由函数 @Override public String doEqualSharding(Collection<String> availableTargetNames, ShardingValue<Long> shardingValue) { for (String tableName : availableTargetNames) { if (tableName.endsWith(shardingValue.getValue() % 2 + "")) { return tableName; } } throw new IllegalArgumentException(); } ...}spring boot快速整合
<dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>3.0.0.M3</version></dependency>sharding: jdbc: ####ds1 datasource: names: ds0 ds0: password: 123 type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.182.131:3306/ds_0 username: root config: sharding: tables: t_order: table-strategy: inline: #### 根据userid 进行分片 sharding-column: user_id algorithm-expression: ds_0.t_order_$->{user_id % 2} actual-data-nodes: ds0.t_order_$->{0..1} props: sql: ### 开启分片日志 show: true